
Un team di ricerca guidato da Mingjiang Wang presso l’Istituto di Tecnologia di Harbin, Shenzhen, in Cina, in collaborazione con l’Università di Huizhou, ha ideato un nuovo metodo per rilevare l’apnea ostruttiva del sonno – basato sulle registrazioni del russare del soggetto.
L’apnea ostruttiva del sonno (OSA) è un disturbo del sonno in cui i muscoli della gola si rilassano e bloccano le vie aeree durante il sonno, causando pause nella respirazione.
Se non trattata, l’OSA può portare a gravi problemi di salute. Un team di ricerca guidato da Mingjiang Wang presso l’Istituto di Tecnologia di Harbin, Shenzhen, in Cina, in collaborazione con l’Università di Huizhou, ha ora ideato un nuovo metodo per rilevare l’OSA – basato sulle registrazioni del russare del soggetto.
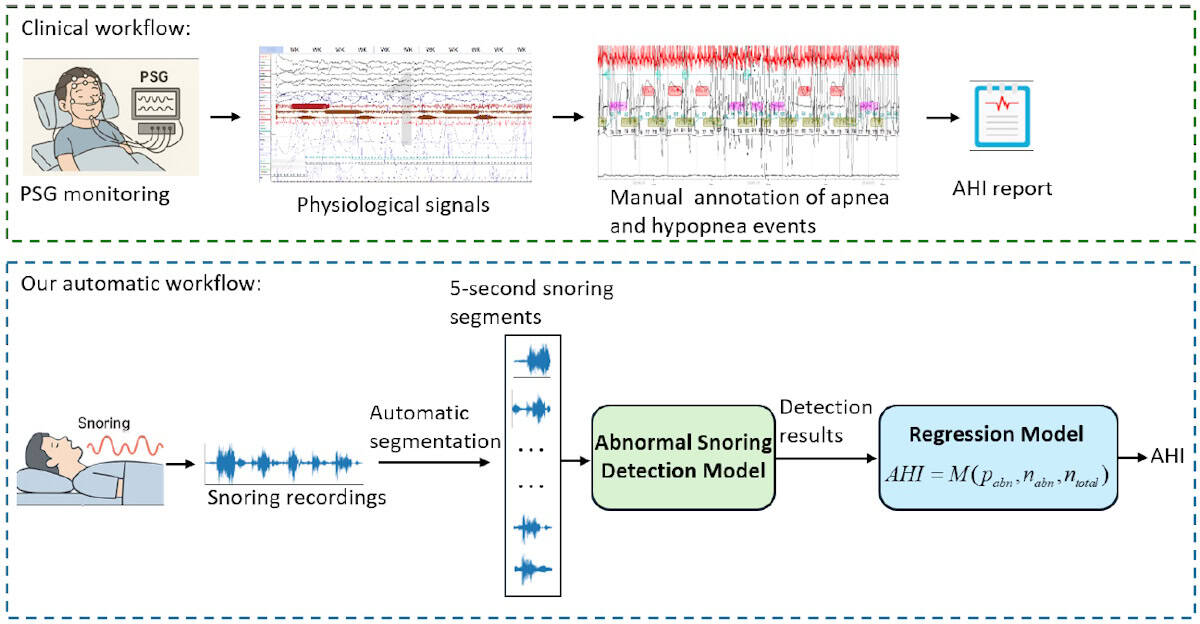
“L’OSA è un disturbo del sonno comune ma sottodiagnosticato,” spiega il primo autore Heng Li. “Lo standard clinico per la diagnosi è la polisonnografia [PSG], che è costosa, richiede tempo e non è adatta allo screening su larga scala o a domicilio.”
La PSG raccoglie molteplici segnali fisiologici tramite vari sensori che i pazienti indossano durante il sonno, potenzialmente alterando i loro schemi di sonno.
“Pertanto, puntiamo a sviluppare un metodo di rilevamento senza contatto usando il russare, che è un sintomo tipico dell’OSA e può essere registrato senza contatto tramite un microfono”, afferma Li.
I modelli acustici del russare, prodotti dalle vibrazioni delle vie aeree superiori, contengono marcatori che riflettono il restringimento e il collasso delle vie aeree. T
Tuttavia, sviluppare un modello affidabile di rilevamento basato sul russare è una sfida, poiché i dataset etichettati per il russare sono scarsi e i rumori variano notevolmente tra gli individui.
In questo studio, pubblicato su Physiological Measurement, il team di ricerca utilizza un modello audio pre-addestrato chiamato Wav2vec 2.0 per affrontare queste sfide.
Trasferendo conoscenze acustiche apprese da dati vocali e audio non etichettati su larga scala, il modello elimina la necessità di dataset etichettati sul russamento.
Wav2vec 2.0 è stato originariamente progettato per il riconoscimento vocale ed è molto intensivo dal punto di vista computazionale, rendendolo inadatto al monitoraggio di routine dell’OSA.
Così il team l’ha adattata ai suoni del russare, rimuovendo strati più rilevanti per il riconoscimento vocale e mantenendo al contempo le caratteristiche acustiche rilevanti per la patologia del russare, con l’obiettivo di ridurre i costi computazionali.
“Non usiamo direttamente il modello pre-addestrato,” spiega Li. “Invece, potiamo gli strati Transformer più alti legati al linguaggio e fondiamo rappresentazioni di basso e medio livello, così che il modello enfatizzi informazioni acustiche legate al russare.”
In collaborazione con l’Ospedale Popolare di Shenzhen, il team ha raccolto registrazioni del sonno da 100 individui con indici di apnea-ipopnea (AHI) che variavano da 2,4 a 68,3 episodi all’ora.
L’AHI – definito come il numero medio di episodi di apnea (in cui la respirazione si interrompe completamente) e ipopnea (respirazione superficiale) per ora di sonno – viene utilizzato per classificare l’OSA da normale (AHI inferiore a 5) fino a grave (30 o superiore).
Tutti i soggetti dormivano nei reparti ospedalieri e venivano monitorati con un dispositivo PSG durante il sonno.
I medici del sonno hanno poi utilizzato i dati PSG per annotare le registrazioni audio con eventi di apnea e ipopnea.
Ogni registrazione è stata divisa in segmenti audio a 5 seconde e assegnata come anomala, se includevano eventi di apnea/ipnoea, o come normale.
Per valutare la capacità del loro quadro di rilevare il russare anomalo, i ricercatori lo hanno confrontato con altri cinque modelli audio pre-addestrati.
Hanno inizialmente effettuato una valutazione dipendente dal soggetto, in cui venivano utilizzati segmenti audio casuali di tutti i soggetti per addestramento, validazione e test.
Tutti i modelli hanno ottenuto buone prestazioni – come previsto quando i dati di addestramento e test provengono dagli stessi soggetti – ma il modello adatto Wav2vec 2.0 ha raggiunto la massima accuratezza e sensibilità.
Il team ha quindi effettuato una valutazione indipendente dal soggetto, che riflette meglio uno scenario reale, assegnando casualmente i dati di ogni soggetto al set di addestramento, validazione o test.
Qui, i metodi esistenti hanno mostrato una precisione ridotta tra il 65% e il 71%, mentre il nuovo modello ha mantenuto una precisione del 73,95%.
“Nei test indipendenti dal soggetto, questo modello adattato ha ottenuto prestazioni migliori rispetto ai modelli di base confrontati, suggerendo una migliore generalizzazione a soggetti non visti”, afferma Li.
Il modello del team era anche significativamente più efficiente dal punto di vista computazionale, un fattore importante per lo screening dell’OSA in scenari domestici o con risorse limitate.
Infine, i ricercatori hanno progettato un quadro di stima AHI basato sul russare, utilizzando il loro modello di rilevamento per identificare segmenti anomali del russare e calcolando una statistica basata sul rapporto – il numero di segmenti anomali diviso per il numero totale di segmenti – per quantificare la gravità dell’OSA. Successivamente hanno utilizzato quattro modelli di regressione lineare comuni per stimare l’AHI per singoli soggetti.
I ricercatori stanno ora indagando su come applicare in modo più efficace modelli audio pre-addestrati all’analisi clinica del russare.
“Ci concentriamo sul rendere questi modelli più leggeri e più adatti allo screening domestico, convalidandone l’efficacia su grandi dataset multicentrici,” racconta Yun Lu, uno degli autori corrispondenti dell’Università di Huizhou, a Physics World.
“Inoltre, intendiamo migliorare l’accuratezza della stima dell’AHI integrando previsioni basate sul russare con ulteriori informazioni fisiologiche non contattabili.”
Immagine: iStock/amenic181